Data Extractor
This tool allows extracting specific data points from multiple XML/JSON/ZIP files simultaneously using XPath queries.
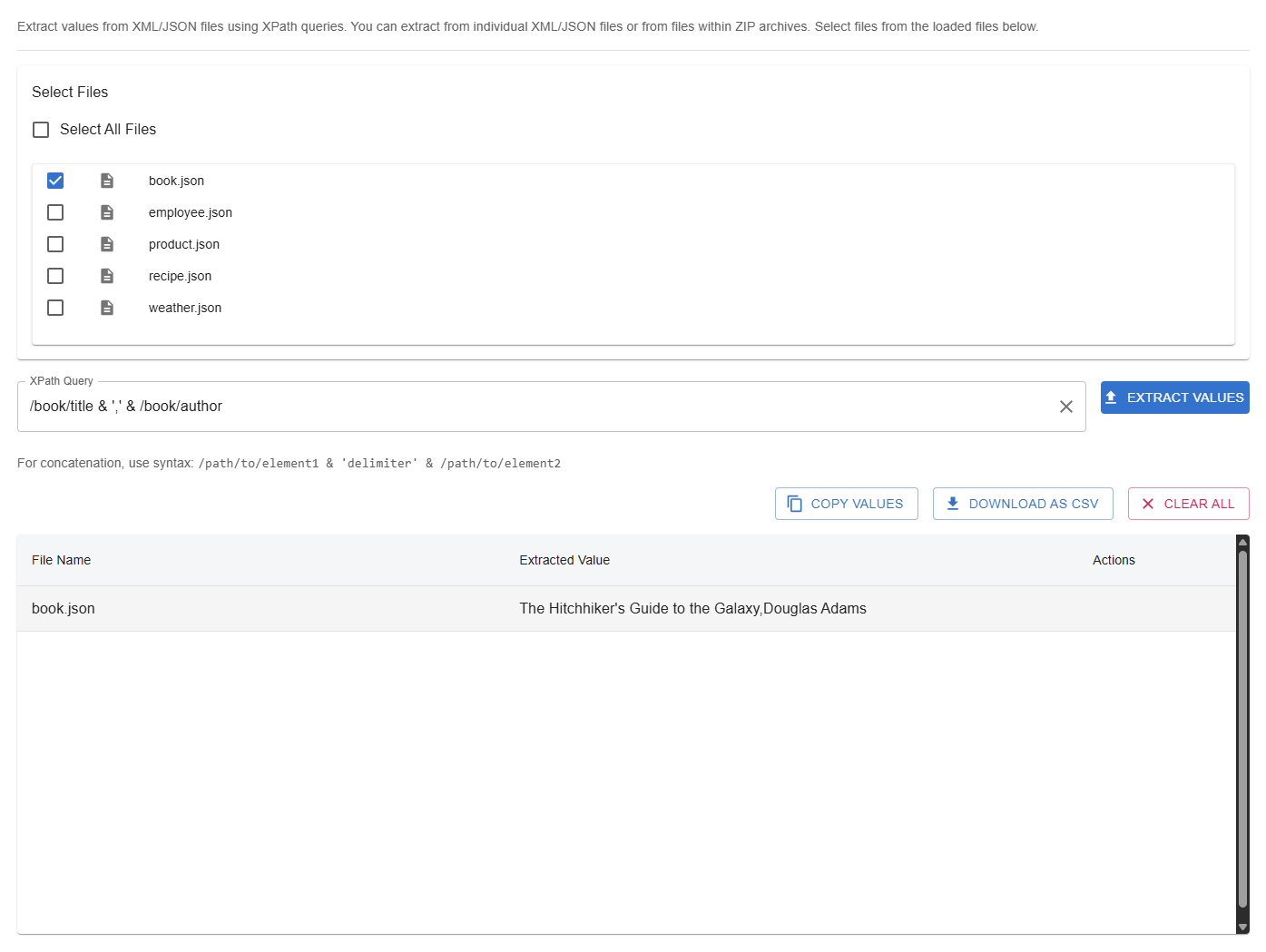
Workflow Overview
- Select Files: Choose the uploaded files or ZIP archives you want to extract data from.
- Enter XPath Query: Define the XPath expression to locate the data you want to extract.
- Extract Values: Run the extraction process to gather matching data from all selected files.
- Review Results: View the extracted data in a table format with file names and corresponding values.
- (Optional) Export Results: Copy values to clipboard or download as CSV for further use.
Features
File Input
- Uploaded Files: All the uploaded files are selectable in the "Select Files" card.
- Uploaded ZIP Archives: The extractor will automatically find and process JSON or XML files within the uploaded ZIP archive, no manual extraction necessary.
XPath Query
- Query Input: An XPath query can be entered in the XPath Query text field.
- Standard XPath: Supports standard XPath 1.0 syntax for navigating the JSON/XML structure and selecting nodes or attribute values (e.g.,
//element/@attribute,/root/path/to/value). These can be copied from the Tree View, see Tree View documentation. -
Concatenation Syntax: Supports a special syntax to concatenate multiple values from the same file using a specified delimiter (e.g., a comma):
/path/to/element1 & 'delimiter' & /path/to/element2- This will find
element1andelement2within each file and outputvalue1 delimiter value2as a single extracted value.
- This will find
- Recent Query Suggestions: When the input field is focused, autocomplete suggestions from the 10 most recently used queries will be shown.
- Namespace Handling: Attempts to handle XML namespaces automatically, including default namespaces and using
local-name()for namespace-agnostic matching when standard methods fail. - Clear Query Button (X): An icon button appears in the input field to clear the current query.
Extraction Process
- Execution: Execution of the query is triggered by pressing
Enterwhile the input field is focused, or clicking theExtract Valuesbutton. - Cancellation: A "Cancel" button appears while the query is processing, allowing the user to cancel the operation.
- Error Handling: If an error occurs (e.g., XPath does not resolve to any elements) an error message will be displayed.
Results Display
-
Results Table: Displays the extracted data with three columns:
File Name: The name of the source file (including ZIP archive name and path within the ZIP, if applicable).Extracted Value: The data extracted from that file based on the XPath query.Actions: Allows opening the file in the viewer, in case it was from a ZIP archive.
- Multiple Matches: If an XPath query matches multiple nodes within a single file, each match will be listed as a separate row in the results table with the same file name.
- Show/Hide XML tags/JSON keys: Results can be displayed with or without the XML tags or JSON keys.
- Syntax Highlighting: With XML tags or JSON keys shown, the values can be syntax highlighted. This can be disabled for better performance, in cases of unusually long rows.
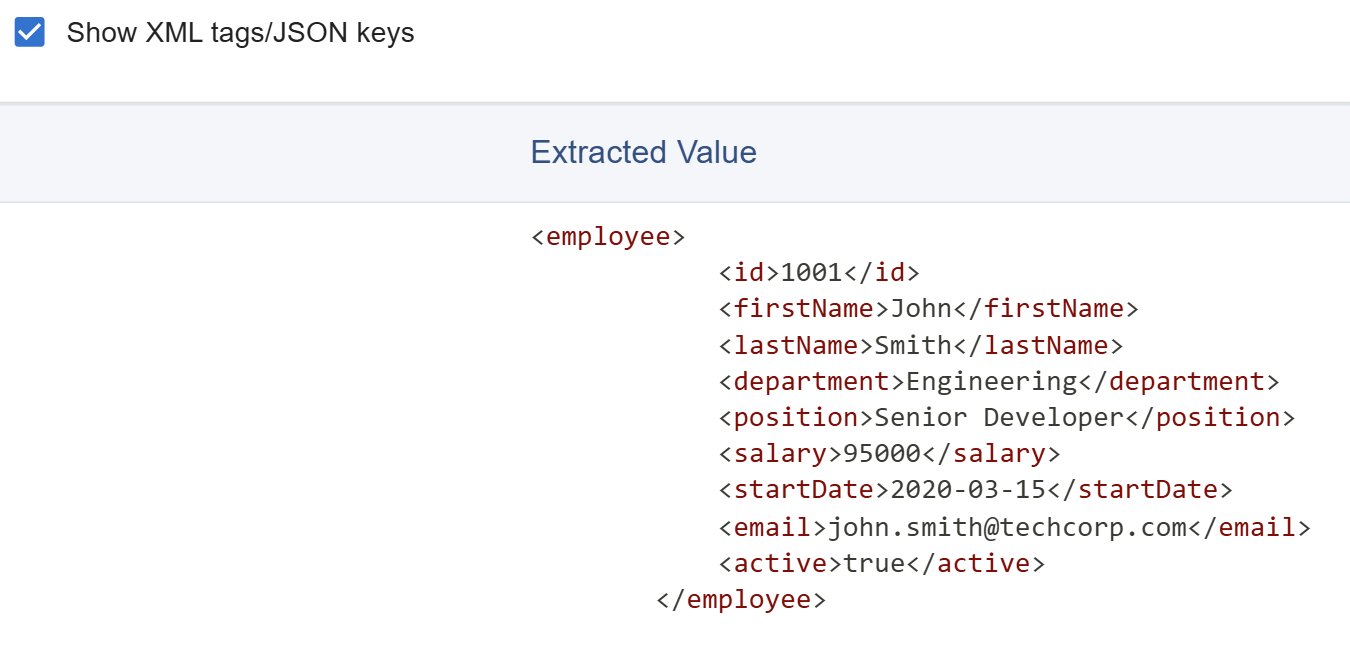
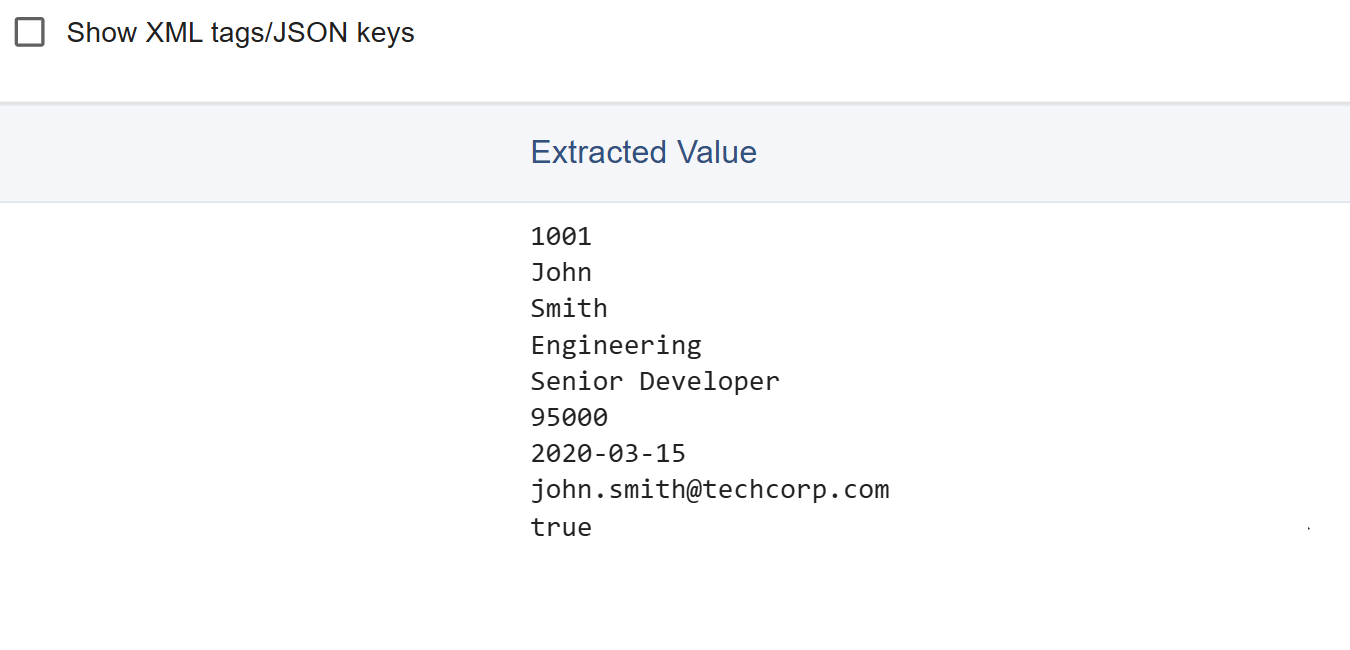
Results Options
Above the results table, several options are available:
- Copy Values: Copies only the text from the "Extracted Value" column to the clipboard, as it is displayed in the results table. If the XML tags or JSON keys are shown, the values will be copied with the tags or keys.
- Download as CSV: Downloads the complete results table (both "File Name" and "Extracted Value" columns) as a comma-separated values (
.csv) file. The XML tags / JSON keys will become headers. Values containing commas or quotes are appropriately escaped. - Clear All: Clears the current XPath query and results table.
Persistence
- The Entered XPath Query will persist view switches and browser refreshes.